GANet
コンテンツ
F. Zhang, et al. “GA-Net: Guided Aggregation Net for End-to-end Stereo Matching” (2019) CVPR 2019
論文情報
リンク
著者
Univeristy of OxfordのTorr Vision Groupのメンバー
- Feihu Zhang Univeristy of Oxford
- Victor Prisacariu Univeristy of Oxford
- Ruigang Yang Baidu Research
- Philip H.S. Torr
概要
- Stereo Machingの有名な古典的手法を学習可能にした以下の2つからなるGuided aggregation (GA)を提案した。
- Semi-Global guided Aggregation (SGA): [SGM]を学習可能にしたLayerで、occulutionがある領域、textureがない/反射がある領域で有効
- Local Guided Aggreagation (LGA): [CostFiltering]を学習可能にしたLayerで、細かい構造、物体境界で有効
- Guided aggregationを利用したGuided Aggragation network (GA-Net)でSOTAを達成
内容
- ネットワークの全体構造は以下
- stacked hourglassで特徴量を得る
- (W, H, D, C)の4次元のcost volumeは左右の画像の特徴量をconcateして作る
- 視差のregressionは[GCNet]と同様にsoft-argmin
- Lossはsmooth-L1
![[Zhang+(2019)] Fig.2より引用](https://nohzen.github.io/Hugo_blog/images/zhang2019_GANet/Fig2.png)
[Zhang+(2019)] Fig.2より引用
- Table 6によると、途中の段階でも視差を出力する?
Guided aggregation (GA)
Semi-Global guided Aggregation (SGA)
- 古典的な[SGM]は、コスト関数の相互作用を一次元方向のみに限定することで、DPで解けるようにしたもの:
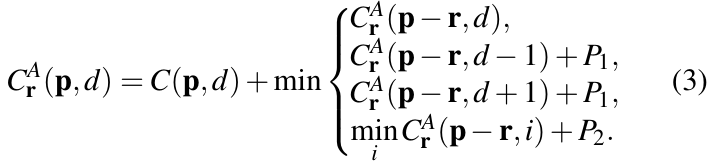
- [SGM]を学習可能なLayerにする。以下が変更点:
- 相互作用項(Penalty)の重みを学習可能にする ($w$はFig2の上側のsubnetで計算。異なる視差に対して重みは共有。)
- 相互作用項のminの代わりにsumを使う([24]でも同じようなことをしている)
- コストじゃなくて確率として扱うので、minじゃなくmaxにする
- さらに、1次元方向のPathに沿って大きくなるのを防ぐために規格化する: (5)式
- 方向は[SGM]では16方向だが、4方向だけにする
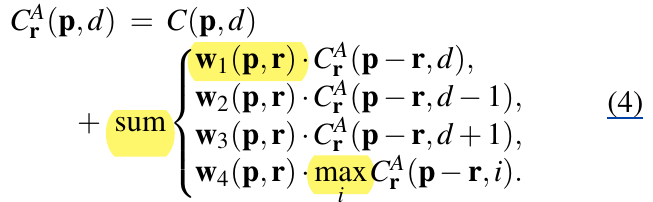
- 各方向に計算した$C_r$のmaxを最終的な出力とする([SGM]では和を使う)
- Blurされるのを防ぐため?
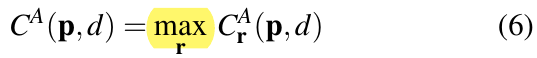
- Blurされるのを防ぐため?
- 広い範囲に渡って影響が伝搬するので、Textureがない領域とかで精度が向上
Local Guided Aggreagation (LGA)
- よく使われるEncoder-Decoder構造のネットワークは薄い構造や物体境界がBlurされやすい
- [CostFiltering]を学習可能なLayerにする
- 重みを学習可能にする ($w$はFig2の上側のsubnetで計算。異なる視差に対して重みは共有。)
- [CostFiltering]では、視差ごとに独立にFilterするが、隣り合う視差からの寄与もある
- 設計は[11]を参考にしている
- [5]と同様に2回繰り返すことでreceptive fieldを広げる
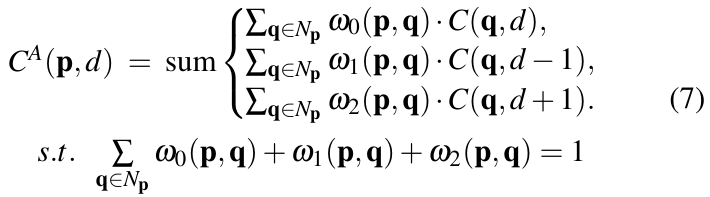
実験
- SceneFlow, KITTI2012, KITTI2015
- [GCNet], [SGMNet]と比較し、処理速度が早く、精度が向上
- Fig3: 3D convを増やすより、GA layerを加えた方が精度が向上する
- Fig4: 難しいシーンにどうSGAとLGAが寄与するか
- 3D convはカーネルサイズ程度の情報しか利用出来ないのに対し、SGAは一層で画像全体の情報を利用できる
感想
- SGAモジュールの式(4, 5, 6)のsum, maxの使い方の必然性は良く分からない
- 式(6)でsumじゃなくてmaxにして、ある方向のコストしか寄与しなくするのは違和感。例えば、画像に斜めのエッジがあるような場合に、ある方向(上下左右)からのみ寄与させるのは微妙な気がする。
- SGMみたいなある方向のみに処理する話は物体検出であった気がするけど、どの論文が忘れてしまった(BBoxの境界の精度を上げる的な話だった気がする)
- LGAモジュールは、3D convとかなり似ている(cost filteringを視差方向も含めて行うという点で)
- 違いは、3D convだと固定weightなのに対して、LGAはweightが別途学習されたもの(Deformable conv v2と同じ)という点だけ?
- 論文では4D cost volumeのチャネル方向についてどういう処理をするか明記されてなかったので、チャネル方向の処理で何か違いはあるかも
- Sec3.1.3に書かれているweightのパラメータ数を見ると、チャネル方向Fについては独立に作用させているっぽい?
- 3D convだとチャネル方向には行列積になっていて、パラメータ数は$K^3F^2$になる
- 3D convの置き換えと言っているが、LGAが実質ほぼ3D convなのに言及がないのが… (SGAとの比較は強調しているが…)
- 視差のRegression 式(9)の$\sigma(-C^A)$にマイナスは必要?
- 先行研究だと、Cは「コスト」(大きいほど寄与が小さくなる)の意味だったので、マイナスがついていた
- 本研究だと、SGAの式(4, 5, 6)あたりを見ると、Cが大きいほど寄与が大きくなる想定で設計されていそうだが…
- 3D convより、提案手法のSGA/LGAが優れていると強調しているが、SOTAモデルGANet-15では、SGAは3層、LGAは2層なのに対し、3D convは15層使っている。筆者らの主張が正しいなら、なぜ3D convを無くすか減らして、SGA/LGAを増やさないのか。
参考文献
- Stereo Matching 古典的な手法
- [10] [CostFiltering] C. Rhemann et al. “Fast Cost-Volume Filtering for Visual Correspondence and Beyond” (2013)
- [9] [SGM] H. Hirschmuller, “Stereo processing by semiglobal matching and mutual information” (2008)
- Stereo Matching DL系
- [15] [DispNet] N. Mayer et al. “A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation” (2015)
- [13] [GCNet] A. Kendall et al. “End-to-End Learning of Geometry and Context for Deep Stereo Regression” (2017)
- [3] [PSMNet] J.-R. Chang, et al. “Pyramid Stereo Matching Network” (2018) 多重解像度で計算量を抑えているが、精度も落ちている
- [31]あまり関係ないがGFの発展、面白そう http://www.feihuzhang.com/SGF.html