AANet
コンテンツ
H. Xu, et al. “AANet: Adaptive Aggregation Network for Efficient Stereo Matching” (2020) CVPR2020
論文情報
リンク
著者
University of Science and Technology of China (USTC)のメンバー
- Haofei Xu
- Juyong Zhang
概要
- stereo matchingで標準的に用いられているcost volumeの3D convの代替となるAdaptive Aggregation Moduleを提案
- Adaptive Aggregation Moduleは以下の2つの相補的なモジュールからなる
- Adaptive Intra-Scale Aggregation (ISA): Deformable conv v2を利用したエッジ保存のFiltering
- Adaptive Cross-Scale Aggregation (CSA): 異なるスケールのcost volumeを混ぜ合わせる(Textureがない領域で精度が向上)
- Adaptive Aggregation Moduleを用いたAdaptive Aggregation Network (AANet)は、SOTAに近い精度で高速
内容
- Adaptive Aggregation Network (AANet)の全体図は以下。
- 3つの解像度で視差を出力し学習する。推論時は、一番大きい解像度W/3 x H/3をRefinementしたものを使う。
![[Xu+(2019)] Fig.2より引用。Refinementは省略されている。](https://nohzen.github.io/Hugo_blog/images/xu2019_AANet/Fig2.png)
[Xu+(2019)] Fig.2より引用。Refinementは省略されている。
cost volume
- 左右の画像から、ResNet系をベース(一部をdeformable convに置き換え)としたFeature Pyramid Networkで1/3, 1/6, 1/12のサイズの特徴量を作る
- 特徴量の内積で3つのスケールのcost volumeを作る
- cost volumeを内積で作るのは[DispNetCorr]と同じ(feature correlationなどとも呼んでいる)。
- [GCNet]などはconcateで作っている。
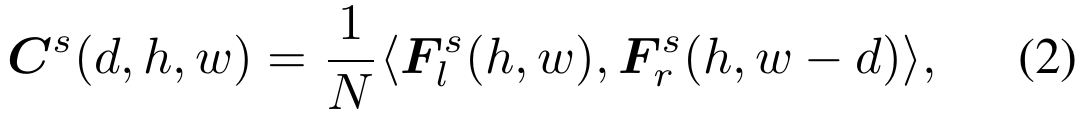
Adaptive Aggregation Module (AAmodule)
GCNet以来、3D convが精度向上に寄与してきたが、処理速度が遅い。 GANetは一部の3D convを別のLayerに置き換えたが、依然として3D convも使っている 以下のISA moduleとCSA moduleを組み合わせたAAmoduleを6つstackする
Adaptive Intra-Scale Aggregation (ISA) module
- Deformable conv v2と同様に、畳み込みのサンプリングの場所$\Delta p_k$ と 追加のweight $m_k$ も学習
- オリジナルのDeformable conv v2では、offset $\Delta p_k$とweight $m_k$は各チャンネルで同じ値だったが、本研究ではdisparityをG=2個のグループに分けて、グループ内で同じ値にする
- dilated convも同時に使う (下式の固定位置サンプリング$p_k$を一定間隔のサンプリングにする?)
- ResNet風に、1x1 -> 3x3 -> 1x1 として3x3のところでDeformable convを使う(ただし、ResNetと違ってチャンネル数=Disparity数は一定)
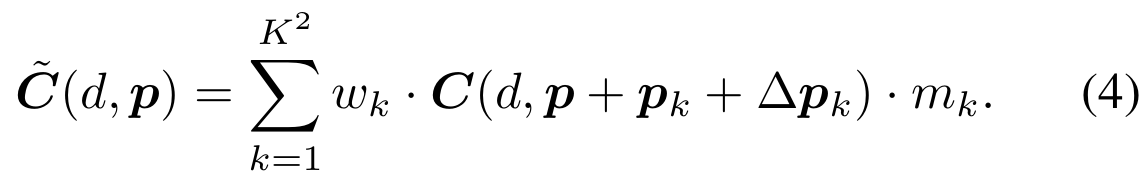
- Adaptive Intra-Scale Aggregation (Deformable conv v2)を使うことで、視差マップのエッジが鈍るのを防げる
- 下図(b)みたいに、単純にcost aggreagationをするとエッジを跨いで平均してしまい、エッジが鈍る
- Deformable convを使うと、下図(c)みたいにサンプリングする場所が同じ物体の場所だけになる(そうなるように学習されるはず)ので、エッジが鈍るのを防げる
![[Xu+(2019)] Fig.1より引用](https://nohzen.github.io/Hugo_blog/images/xu2019_AANet/Fig1.png)
[Xu+(2019)] Fig.1より引用
- 疑問
- Cost volumeに幅・高さ・視差の次元に加えて、チャネル次元はある?
→ [GCNet]などと違って、内積でcost volumeを作っているので、チャンネル次元は消えている - 追加のweight $m_k$を導入することで、content adaptive(position specific)になると強調しているが、$m_k$も元のweightとそこまで変わらないような(畳み込みで計算されたものって点は違うが)
- Cost volumeに幅・高さ・視差の次元に加えて、チャネル次元はある?
Adaptive Cross-Scale Aggregation (CSA) module
- Textureがない領域では、荒い解像度でStereo Matchingするといい[21, 36]
- そこで、いくつかのスケールでのcost aggregationに相互作用を入れた[44]をNNにする: 関連 [33, 39, 30, 35]
- $f$にはHRNet[32]の式を採用。解像度を合わせるための畳み込み層。
- HRNetと違い、1/2解像度にした時にはチャンネル数(disparity数)を半分にする(解像度が下がると、disparityの解像度も下がるので)
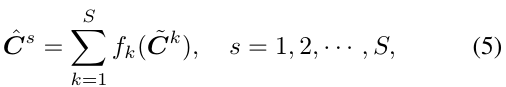
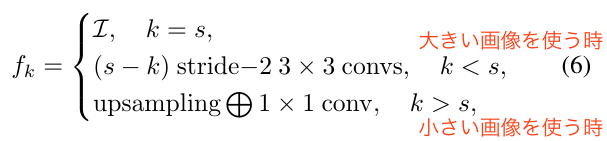
他
- Refinement
- [StereoDRNet]と同じネットワークで
- 1/3の荒い視差マップを、1/3 -> 1/2 -> 1 と2段階で元解像度にする
- [StereoDRNet]みたいに、Occlutionの出力や、photometric error/geometric errorの入力はしない?
- [GCNet]と同じsoft-argminで視差を推定
- Loss: [PSMNet]と同じsmooth-L1 loss
- 前段の荒い視差推定が3つのスケールで、後段のRefinementが2つのスケールで出力を持つので、合計5つのLossの重み付き和が最終的なLoss
- Distillation: KITTIのように、SparseなGTしかない場合は、GTがないPixelでは他のネットワーク(GANetなど)の推論結果をGTとする
実験
- SceneFlow, KITTI2012, KITTI2015, Middlebury
- 高速でSOTAに近い精度(KITTIではSOTAの[GANet], [GwcNet]には負けている)
- Ablation study:
- Table 1, Fig 3: 基本はISA, CSAがあった方がいい (KITTI2015のD1指標では、ISAはない方がいい)
- Fig5: KITTIでGTがない領域(空とか)では、Distillationを使った方がアーティファクトが減る(D1は向上して、EPEは悪化)
- Table 2: 先行研究の3D convを提案手法のAdaptive Aggregation Moduleに置き換えると精度が向上し、処理時間が短くなる
- AANet+: GANet-AA([GANet]の3D convをAAmoduleに置き換えたもの)のRefinement部分を改善したモデル
- AANetより高精度で高速
感想
- AANetを長々と説明していたのに、AANet+(GANetベースのモデル)の方が精度が良くて処理速度も早いみたい…
- 3D convだと空間方向に加えて、視差方向のFilterにもなっているが、それが失われる?
- 3D convだと、cost volumeは4次元(C, D, W, H)で、DWH方向には畳み込み、C方向には行列積(fully connected)
- AAmoduleだと、cost volumeは3次元(D, W, H)で、WH方向には畳み込み、D方向には行列積(fully connected)
- たぶん、AAmoduleの方が視差方向には計算量が多いFilterになっている
- 視差方向も空間方向と同じで、あまりに値が離れているものは関連して無さそうなので、畳み込みの方が良さそうな気がする
- cost volumeを3次元(D, W, H)で、3D conv(ただしチャンネル数は1)とかにしたら、提案手法より良くなったりしないだろうか
- 今回の結果に寄与しているのが、ISA(Deformable conv)なのか、CSA(cost volumeを複数スケール持つ)なのか、cost volumeを4次元から3次元にしたこと(concateでなく内積でcost volumeを作る)なのか
- ISAやCSAは3D convとも組み合わせられると思うので、試してみたい
参考文献
- Stereo Matching
- [20] [DispNetCorr] N. Mayer et al. “A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation” (2015)
- [14] [GCNet] A. Kendall, et al. “End-to-end learning of geometry and context for deep stereo regression” (2017)
- [6] [DeepPruner] Shivam Duggal, et al. “Deeppruner: Learning efficient stereo matching via differentiable patchmatch” (2019) 本研究と同時に使える
- [3] [StereoDRNet] R. Chabra, et al. “Stereodrnet: Dilated residual stereonet” (2019)
- Deformable conv
- [5] J. Dai, et al. “Deformable convolutional networks” (2017)
- [45] X. Zhu, et al. “Deformable convnets v2: More deformable, better results” (2019)
- Dilated conv
- [41] F. Yu, et al. “Dilated residual networks” (2017)
- Cross-scale
- [44] K. Zhang, et al. “Cross-scale cost aggregation for stereo matching” (2014)
- [32] [HRNet] K. Sun, et al. “Deep high-resolution representation learning for human pose estimation” (2019)
- Distillation
- [10] G. Hinton, et al. “Distilling the knowledge in a neural network” (2015)